キャンセル
一次予選参加(☆初参加)
プログラム名
elmo
開発者名
CPUとクロック
 4930K
4930K 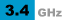
プロセッサ数/総コア数/メモリ
1 / 6 / 32GB
OS / 使用言語 /使用ライブラリ
 /
/
 /
/ 
アピール文書
wcsc24 elmoアピール文書v1.2 2014.3.30 瀧澤
◆ 開発方針
学習部を中心に開発を行っています。 KKP, KPPの評価関数に一定の制約を加えることで棋力向上を図っています。 基本的に学習結果(param.h,fv.bin)の変更であり、一部高速化を除いてBonanza v6.0のプログラムをそのまま利用しています。
◆ elmoの独自改良
1.特徴の類似性に着目した正則化項の導入 Bonanzaの目的関数に新たな正則化項を追加しています。 正則化項は学習によって算出される評価関数に一定の制約を与え、 (人間的な)事前知識を埋め込むことが可能となります。
現時点の実装ではBonanzaで用いられている、駒の位置関係に基づく特徴について 「相対的な位置関係が同一」かつ「近傍に存在する」特徴の評価値が滑らかに変化するように正則化項を導入しています。 (急峻な変化は許容し、イレギュラーな変化にペナルティをつけるようにしています。) (画像処理で言うところのTotal Variationです)
2.重要度の低いKPP成分の評価値を低減
Bonanzaでは 駒割、KP、KKP、KPPの特徴を評価関数に利用していますが、 KPPは表現能力が高い反面、特徴当たりの学習データ数が必然的に少ないために重要度の高い特徴と偶然同時に発生する重要度の低い特徴にも値が付く傾向があります。
これは重要度の高い特徴に十分な値が付かないことを意味します。
この問題は学習局面数等を増やすことで低減されるものですが、より直接的な対処を検討します。
現時点の実装では学習の途中において、重要度の低いと思われる特徴(※)を検出し、その評価値を低減するフィルタを適用することで、より重要度の高い特徴に値をつけるように誘導しています。
(※) KPやKKPで十分評価可能と見なせるKPP、としています。
◆ 一言
対オリジナルの勝率は現状4~5割程度です。 学習棋譜数(3.5万)と探索深さ(2)で劣後しているのでこれを解消してあげれば勝ち越せると思っていますが今まで散々試行錯誤してきたことを考えると何とも言えないです。
今後はもう一歩踏み込んだモデル化をしたいと思います。